| 4.4. 解决中文乱码问题 | ||
|---|---|---|
 |
4. UseModWiki | 
|
| 4.4. 解决中文乱码问题 | ||
|---|---|---|
|
|
4. UseModWiki |
|
在 UseModWiki 0.92 版中使用中文会出现乱码问题,如前面刚刚提到的,本来应该显示为:“在这里添加新的页面。”,结果显示成了“在这里添加新的颐妗?”。UseModWiki 1.0 基本解决了这个问题,如果使用 1.0 版本的 UseModWiki 可以忽略本节。
仔细对照两段文字的编码,发现是"页"字的编码为 "0xD2 0xB3",而后一个字节 "0xB3" 被 UseModWiki 给过滤掉了。
我们无需重造车轮,这个问题其它人一定已经遇到,去网上查一查,看看有没有解决方案。远在天边,近在眼前,UseModWiki 网站即有解决之道:
WikiPaches: UseModWiki 的扩展
UtfEight: 解决 Utf8 编码的乱码问题
EscapeFS: 解决编码的乱码问题
我们查看一下 UseModWiki 的脚本,可以看出罪魁祸首:
166: # Field separators are used in the URL-style patterns below. 167: $FS = "\xb3"; # The FS character is a superscript "3" 168: $FS1 = $FS . "1"; # The FS values are used to separate fields 169: $FS2 = $FS . "2"; # in stored hashtables and other data structures. 170: $FS3 = $FS . "3"; # The FS character is not allowed in user data. 1160: $pageText =~ s/$FS//g; # Remove separators (paranoia) ... ... ... ...
由于 UseModWiki 采用字符 '0xB3' 作为数据存储的字段分隔符,为了防止用户输入该字符破坏文件的结构,因此过滤该字符。"UtfEight" 的修改方法,是只替换 $F1, $F2, $F3 定界符,而不替换 $F 定界符。对 wiki.pl 代码的修改如下:
--- wiki_92.pl 2002-12-22 12:01:49.000000000 -0600
+++ wiki_utf8.cgi 2002-12-23 10:44:38.000000000 -0600
@@ -82,7 +82,7 @@
$EditNote = ""; # HTML notice above buttons on edit page
$MaxPost = 1024 * 210; # Maximum 210K posts (about 200K for pages)
$NewText = ""; # New page text ("" for default message)
-$HttpCharset = ""; # Charset for pages, like "iso-8859-2"
+$HttpCharset = "UTF-8"; # Charset for pages, like "iso-8859-2"
$UserGotoBar = ""; # HTML added to end of goto bar
# Major options:
@@ -986,6 +986,7 @@
return $q->header(-cookie=>$cookie);
}
if ($HttpCharset ne '') {
+ $q->charset($HttpCharset);
return $q->header(-type=>"text/html; charset=$HttpCharset");
}
return $q->header();
@@ -1157,7 +1157,7 @@
%SaveNumUrl = ();
$SaveUrlIndex = 0;
$SaveNumUrlIndex = 0;
- $pageText =~ s/$FS//g; # Remove separators (paranoia)
+ $pageText =~ s/$FS[123]//g; # Remove separators (paranoia)
if ($RawHtml) {
$pageText =~ s/<html>((.|\n)*?)<\/html>/&StoreRaw($1)/ige;
}
@@ -1678,7 +1678,7 @@
%SaveNumUrl = ();
$SaveUrlIndex = 0;
$SaveNumUrlIndex = 0;
- $diff =~ s/$FS//g;
+ $diff =~ s/$FS[123]//g;
$diff = &CommonMarkup($diff, 0, 1); # No images, all patterns
$diff =~ s/$FS(\d+)$FS/$SaveUrl{$1}/ge; # Restore saved text
$diff =~ s/$FS(\d+)$FS/$SaveUrl{$1}/ge; # Restore nested saved text
@@ -3214,8 +3214,8 @@
&ReportError(Ts('[[%s]] cannot be defined.', $id));
return;
}
- $string =~ s/$FS//g;
- $summary =~ s/$FS//g;
+ $string =~ s/$FS[123]//g;
+ $summary =~ s/$FS[123]//g;
$summary =~ s/[\r\n]//g;
# Add a newline to the end of the string (if it doesn't have one)
$string .= "\n" if (!($string =~ /\n$/));
@@ -3820,7 +3820,7 @@
# Much of this is taken from the common markup
%SaveUrl = ();
$SaveUrlIndex = 0;
- $text =~ s/$FS//g; # Remove separators (paranoia)
+ $text =~ s/$FS[123]//g; # Remove separators (paranoia)
if ($RawHtml) {
$text =~ s/(<html>((.|\n)*?)<\/html>)/&StoreRaw($1)/ige;
}
修改的好处是,保持了和原有数据的兼容性,原有的 Wiki 页面能够正常显示;缺点是修改不彻底,如果输入字符 "页1"、 "页2" 或 "页3",还会出现乱码。但毕竟这样的机会比较少,而且在汉字"页"和数字1,2,3 之间加上空格,就可以避免这种情况下的乱码。
采用用多个字符来代替 UseModWiki 的确省分隔符 '0xB3',虽然能够比较好的解决乱码问题,但是可能会造成原有数据内容的解码错误。具体参见: http://www.usemod.com/cgi-bin/wiki.pl?WikiPatches/EscapeFS。
修改好后,我们再次打开我们搭建好的 Wiki 网站,可以看到乱码问题已经解决:
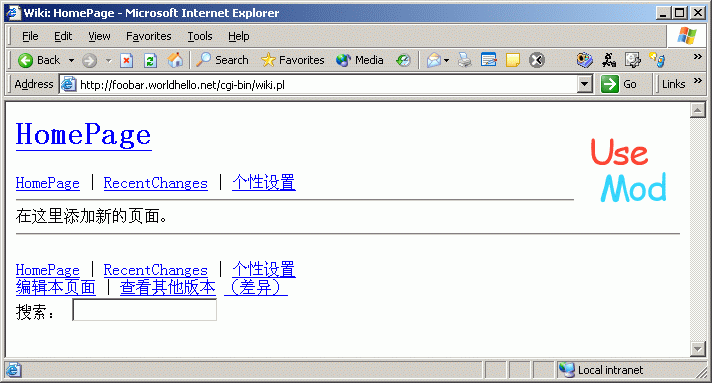
汉化后的 UseModWiki 界面
UseModWiki 1.0 版本默认采用上面所述的方法来支持8比特的字符集。但是我们从上面描述的修改方法可以看出来仍然有出现乱码的可能,例如输入"页1页2"等就会显示为乱码。为了尽最大可能的不出现乱码,还可以将字段分隔符定义为多字节。下面代码摘自 wiki.pl(1.0版):
...
$NewFS = 0; # 1 = new multibyte $FS, 0 = old $FS
...
if ($NewFS) {
$FS = "\x1e\xff\xfe\x1e"; # An unlikely sequence for any charset
} else {
$FS = "\xb3"; # The FS character is a superscript "3"
}
$FS1 = $FS . "1"; # The FS values are used to separate fields
$FS2 = $FS . "2"; # in stored hashtables and other data structures.
$FS3 = $FS . "3"; # The FS character is not allowed in user data.
...
在 config 中定义 $NewFS 为 1, 则用多字节的分隔符,但是以前采用 0xb3 为分隔符的 wiki 服务器端数据需要进行转换,否则不能使用。用如下命令就可以完成转换:sed -e "s/\xb3\([1-3]\)/\x1e\xff\xfe\x1e\1/g"。
Copyright © 2006 WorldHello 开放文档之源 计划 |
|
|
 |
|
| 4.3. UseModWiki 的汉化 |  |
4.5. 学写 UseModWiki 网页 |